
BCH code
In [[codin15}}). We will consider different values of }} its minimal polynomial over is

The minimal polynomials of the first fourteen powers of are




The BCH code with  has generator polynomial
has generator polynomial

It has minimal at least 3 and corrects up to one error. Since the generator polynomial is of degree 4, this code has 11 data bits and 4 checksum bits.
The BCH code with  has generator polynomial
has generator polynomial

It has minimal Hamming distance at least 5 and corrects up to two errors. Since the generator polynomial is of degree 8, this code has 7 data bits and 8 checksum bits.
The BCH code with  has generator polynomial
has generator polynomial

It has minimal Hamming distance at least 7 and corrects up to three errors. Since the generator polynomial is of degree 10, this code has 5 data bits and 10 checksum bits.
(This particular generator polynomial has a real-world application, in the format patterns of the .)
The BCH code with  and higher has generator polynomial
and higher has generator polynomial

This code has minimal Hamming distance 15 and corrects 7 errors. It has 1 data bit and 14 checksum bits. In fact, this code has only two codewords: 000000000000000 and 111111111111111.
Contents
General BCH codes
General BCH codes differ from primitive narrow-sense BCH codes in two respects.
First, the requirement that  be a primitive element of
be a primitive element of  can be relaxed. By relaxing this requirement, the code length changes from
can be relaxed. By relaxing this requirement, the code length changes from  to
to  the of the element
the of the element 
Second, the consecutive roots of the generator polynomial may run from  instead of
instead of 
Definition. Fix a finite field  where
where  is a prime power. Choose positive integers
is a prime power. Choose positive integers  such that
such that 
 and
and  is the of modulo
is the of modulo 
As before, let be a primitive 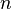 th root of unity in
th root of unity in  and let
and let  be the over
be the over  of
of  for all
for all  The generator polynomial of the BCH code is defined as the
The generator polynomial of the BCH code is defined as the 
Note: if  as in the simplified definition, then
as in the simplified definition, then  is 1, and the order of modulo
is 1, and the order of modulo  is
is  Therefore, the simplified definition is indeed a special case of the general one.
Therefore, the simplified definition is indeed a special case of the general one.
Special cases
- A BCH code with
 is called a narrow-sense BCH code.
is called a narrow-sense BCH code. - A BCH code with is called primitive.
The generator polynomial  of a BCH code has coefficients from
of a BCH code has coefficients from  In general, a cyclic code over
In general, a cyclic code over  with as the generator polynomial is called a BCH code over
with as the generator polynomial is called a BCH code over  The BCH code over with as the generator polynomial is called a . In other words, a Reed–Solomon code is a BCH code where the decoder alphabet is the same as the channel alphabet.
The BCH code over with as the generator polynomial is called a . In other words, a Reed–Solomon code is a BCH code where the decoder alphabet is the same as the channel alphabet.
Properties
The generator polynomial of a BCH code has degree at most  . Moreover, if
. Moreover, if  and , the generator polynomial has degree at most
and , the generator polynomial has degree at most  .
.
Each minimal polynomial has degree at most . Therefore, the least common multiple of  of them has degree at most . Moreover, if
of them has degree at most . Moreover, if  then
then  for all
for all  . Therefore, is the least common multiple of at most
. Therefore, is the least common multiple of at most  minimal polynomials for odd indices
minimal polynomials for odd indices  each of degree at most .
each of degree at most .
A BCH code has minimal Hamming distance at least  .
.
Suppose that  is a code word with fewer than non-zero terms. Then
is a code word with fewer than non-zero terms. Then

Recall that are roots of  hence of . This implies that
hence of . This implies that  satisfy the following equations, for each
satisfy the following equations, for each  :
:

In matrix form, we have

The determinant of this matrix equals

The matrix  is seen to be a , and its determinant is
is seen to be a , and its determinant is

which is non-zero. It therefore follows that  hence
hence 
A BCH code is cyclic. A polynomial code of length is cyclic if and only if its generator polynomial divides  Since is the minimal polynomial with roots
Since is the minimal polynomial with roots  it suffices to check that each of is a root of This follows immediately from the fact that is, by definition, an th root of unity.
it suffices to check that each of is a root of This follows immediately from the fact that is, by definition, an th root of unity.
Encoding
Decoding
There are many algorithms for decoding BCH codes. The most common ones follow this general outline:
- Calculate the syndromes sj for the received vector
- Determine the number of errors t and the error locator polynomial Λ(x) from the syndromes
- Calculate the roots of the error location polynomial to find the error locations Xi
- Calculate the error values Yi at those error locations
- Correct the errors
During some of these steps, the decoding algorithm may determine that the received vector has too many errors and cannot be corrected. For example, if an appropriate value of t is not found, then the correction would fail. In a truncated (not primitive) code, an error location may be out of range. If the received vector has more errors than the code can correct, the decoder may unknowingly produce an apparently valid message that is not the one that was sent.
Calculate the syndromes
The received vector  is the sum of the correct codeword
is the sum of the correct codeword  and an unknown error vector
and an unknown error vector  The syndrome values are formed by considering as a polynomial and evaluating it at
The syndrome values are formed by considering as a polynomial and evaluating it at  Thus the syndromes are
Thus the syndromes are

for  to
to  Since
Since  are the zeros of of which
are the zeros of of which  is a multiple,
is a multiple,  Examining the syndrome values thus isolates the error vector so one can begin to solve for it.
Examining the syndrome values thus isolates the error vector so one can begin to solve for it.
If there is no error,  for all
for all  If the syndromes are all zero, then the decoding is done.
If the syndromes are all zero, then the decoding is done.
Calculate the error location polynomial
If there are nonzero syndromes, then there are errors. The decoder needs to figure out how many errors and the location of those errors.
If there is a single error, write this as  where is the location of the error and
where is the location of the error and  is its magnitude. Then the first two syndromes are
is its magnitude. Then the first two syndromes are


so together they allow us to calculate and provide some information about (completely determining it in the case of Reed–Solomon codes).
If there are two or more errors,

It is not immediately obvious how to begin solving the resulting syndromes for the unknowns  and
and  First step is finding locator polynomial
First step is finding locator polynomial
 compatible with computed syndromes and with minimal possible
compatible with computed syndromes and with minimal possible 
Two popular algorithms for this task are:
Peterson–Gorenstein–Zierler algorithm
Peterson’s algorithm is the step 2 of the generalized BCH decoding procedure. Peterson’s algorithm is used to calculate the error locator polynomial coefficients  of a polynomial
of a polynomial

Now the procedure of the Peterson–Gorenstein–Zierler algorithm. Expect we have at least 2t syndromes sc,…,sc+2t−1. Let v = t.
- Start by generating the
 matrix with elements that are syndrome values
matrix with elements that are syndrome values

- Generate a
 vector with elements
vector with elements

- Let
 denote the unknown polynomial coefficients, which are given by
denote the unknown polynomial coefficients, which are given by

- Form the matrix equation

- If the determinant of matrix is nonzero, then we can actually find an inverse of this matrix and solve for the values of unknown values.
- If
 then follow
then follow
ifthen declare an empty error locator polynomial stop Peterson procedure. end set
continue from the beginning of Peterson's decoding by making smaller
- After you have values of , you have with you the error locator polynomial.
- Stop Peterson procedure.
Factor error locator polynomial
Now that you have the  polynomial, its roots can be found in the form
polynomial, its roots can be found in the form  by brute force for example using the Chien search algorithm. The exponential powers of the primitive element will yield the positions where errors occur in the received word; hence the name ‘error locator’ polynomial.
by brute force for example using the Chien search algorithm. The exponential powers of the primitive element will yield the positions where errors occur in the received word; hence the name ‘error locator’ polynomial.
The zeros of Λ(x) are α−i1, …, α−iv.
Calculate error values
Once the error locations are known, the next step is to determine the error values at those locations. The error values are then used to correct the received values at those locations to recover the original codeword.
For the case of binary BCH, (with all characters readable) this is trivial; just flip the bits for the received word at these positions, and we have the corrected code word. In the more general case, the error weights  can be determined by solving the linear system
can be determined by solving the linear system

Forney algorithm
However, there is a more efficient method known as the Forney algorithm.
Let


And the error evaluator polynomial

Finally:

where

Than if syndromes could be explained by an error word, which could be nonzero only on positions  , then error values are
, then error values are

For narrow-sense BCH codes, c = 1, so the expression simplifies to:

Explanation of Forney algorithm computation
It is based on and techniques of .
Consider  and for the sake of simplicity suppose
and for the sake of simplicity suppose  for
for  and
and  for
for  Then
Then


We want to compute unknowns  and we could simplify the context by removing the
and we could simplify the context by removing the  terms. This leads to the error evaluator polynomial
terms. This leads to the error evaluator polynomial

Thanks to  we have
we have

Thanks to (the Lagrange interpolation trick) the sum degenerates to only one summand for 

To get we just should get rid of the product. We could compute the product directly from already computed roots  of
of  but we could use simpler form.
but we could use simpler form.
As

we get again only one summand in

So finally

This formula is advantageous when one computes the formal derivative of form

yielding:
where
Decoding based on extended Euclidean algorithm
An alternate process of finding both the polynomial Λ and the error locator polynomial is based on Yasuo Sugiyama’s adaptation of the . Correction of unreadable characters could be incorporated to the algorithm easily as well.
Let  be positions of unreadable characters. One creates polynomial localising these positions
be positions of unreadable characters. One creates polynomial localising these positions  Set values on unreadable positions to 0 and compute the syndromes.
Set values on unreadable positions to 0 and compute the syndromes.
As we have already defined for the Forney formula let 
Let us run extended Euclidean algorithm for locating least common divisor of polynomials  and
and  The goal is not to find the least common divisor, but a polynomial
The goal is not to find the least common divisor, but a polynomial  of degree at most
of degree at most  and polynomials
and polynomials  such that
such that  Low degree of guarantees, that
Low degree of guarantees, that  would satisfy extended (by
would satisfy extended (by  ) defining conditions for
) defining conditions for 
Defining  and using
and using  on the place of in the Fourney formula will give us error values.
on the place of in the Fourney formula will give us error values.
The main advantage of the algorithm is that it meanwhile computes  required in the Forney formula.
required in the Forney formula.
Explanation of the decoding process
The goal is to find a codeword which differs from the received word minimally as possible on readable positions. When expressing the received word as a sum of nearest codeword and error word, we are trying to find error word with minimal number of non-zeros on readable positions. Syndrom  restricts error word by condition
restricts error word by condition

We could write these conditions separately or we could create polynomial

and compare coefficients near powers  to
to 

Suppose there is unreadable letter on position  we could replace set of syndromes
we could replace set of syndromes  by set of syndromes
by set of syndromes  defined by equation
defined by equation  Suppose for an error word all restrictions by original set of syndromes hold, than
Suppose for an error word all restrictions by original set of syndromes hold, than

New set of syndromes restricts error vector

the same way the original set of syndromes restricted the error vector  Note, that except the coordinate where we have
Note, that except the coordinate where we have  an
an  is zero, if
is zero, if  For the goal of locating error positions we could change the set of syndromes in the similar way to reflect all unreadable characters. This shortens the set of syndromes by
For the goal of locating error positions we could change the set of syndromes in the similar way to reflect all unreadable characters. This shortens the set of syndromes by 
In polynomial formulation, the replacement of syndromes set by syndromes set leads to

Therefore,

After replacement of  by , one would require equation for coefficients near powers
by , one would require equation for coefficients near powers 
One could consider looking for error positions from the point of view of eliminating influence of given positions similarly as for unreadable characters. If we found  positions such that eliminating their influence leads to obtaining set of syndromes consisting of all zeros, than there exists error vector with errors only on these coordinates. If denotes the polynomial eliminating the influence of these coordinates, we obtain
positions such that eliminating their influence leads to obtaining set of syndromes consisting of all zeros, than there exists error vector with errors only on these coordinates. If denotes the polynomial eliminating the influence of these coordinates, we obtain

In Euclidean algorithm, we try to correct at most  errors (on readable positions), because with bigger error count there could be more codewords in the same distance from the received word. Therefore, for we are looking for, the equation must hold for coefficients near powers starting from
errors (on readable positions), because with bigger error count there could be more codewords in the same distance from the received word. Therefore, for we are looking for, the equation must hold for coefficients near powers starting from

In Forney formula, could be multiplied by a scalar giving the same result.
It could happen that the Euclidean algorithm finds of degree higher than having number of different roots equal to its degree, where the Fourney formula would be able to correct errors in all its roots, anyway correcting such many errors could be risky (especially with no other restrictions on received word). Usually after getting of higher degree, we decide not to correct the errors. Correction could fail in the case has roots with higher multiplicity or the number of roots is smaller than its degree. Fail could be detected as well by Forney formula returning error outside the transmitted alphabet.
Correct the errors
Using the error values and error location, correct the errors and form a corrected code vector by subtracting error values at error locations.
Decoding examples
Decoding of binary code without unreadable characters
Consider a BCH code in GF(24) with  and
and  . (This is used in .) Let the message to be transmitted be [1 1 0 1 1], or in polynomial notation,
. (This is used in .) Let the message to be transmitted be [1 1 0 1 1], or in polynomial notation,  The “checksum” symbols are calculated by dividing
The “checksum” symbols are calculated by dividing  by and taking the remainder, resulting in
by and taking the remainder, resulting in  or [ 1 0 0 0 0 1 0 1 0 0 ]. These are appended to the message, so the transmitted codeword is [ 1 1 0 1 1 1 0 0 0 0 1 0 1 0 0 ].
or [ 1 0 0 0 0 1 0 1 0 0 ]. These are appended to the message, so the transmitted codeword is [ 1 1 0 1 1 1 0 0 0 0 1 0 1 0 0 ].
Now, imagine that there are two bit-errors in the transmission, so the received codeword is [ 1 0 1 1 1 0 0 0 1 0 1 0 0 ]. In polynomial notation:

In order to correct the errors, first calculate the syndromes. Taking  we have
we have 



 and
and  Next, apply the Peterson procedure by row-reducing the following augmented matrix.
Next, apply the Peterson procedure by row-reducing the following augmented matrix.
![left [ S_{3 times 3} | C_{3 times 1} right ] = begin{bmatrix}s_1&s_2&s_3&s_4 s_2&s_3&s_4&s_5 s_3&s_4&s_5&s_6end{bmatrix} = begin{bmatrix}1011&1001&1011&1101 1001&1011&1101&0001 1011&1101&0001&1001end{bmatrix} Rightarrow begin{bmatrix}0001&0000&1000&0111 0000&0001&1011&0001 0000&0000&0000&0000end{bmatrix}](/upload/en/images/math/d/a/3/da3e42dcac8419e6b07afa7ec1dbd6ec.png)
Due to the zero row, is singular, which is no surprise since only two errors were introduced into the codeword. However, the upper-left corner of the matrix is identical to , which gives rise to the solution 
 The resulting error locator polynomial is
The resulting error locator polynomial is  which has zeros at
which has zeros at  and
and  The exponents of correspond to the error locations. There is no need to calculate the error values in this example, as the only possible value is 1.
The exponents of correspond to the error locations. There is no need to calculate the error values in this example, as the only possible value is 1.
Decoding with unreadable characters
Suppose the same scenario, but the received word has two unreadable characters [ 1 0 ? 1 1 ? 0 0 1 0 1 0 0 ]. We replace the unreadable characters by zeros while creating the polynom reflecting their positions  We compute the syndromes
We compute the syndromes  and
and  (Using log notation which is independent on GF(24) isomorphisms. For computation checking we can use the same representation for addition as was used in previous example. Hexadecimal description of the powers of are consecutively 1,2,4,8,3,6,C,B,5,A,7,E,F,D,9 with the addition based on bitwise xor.)
(Using log notation which is independent on GF(24) isomorphisms. For computation checking we can use the same representation for addition as was used in previous example. Hexadecimal description of the powers of are consecutively 1,2,4,8,3,6,C,B,5,A,7,E,F,D,9 with the addition based on bitwise xor.)
Let us make syndrome polynomial

compute

Run the extended Euclidean algorithm:
![begin{align} begin{pmatrix}S(x)Gamma(x)\ x^6end{pmatrix} &= begin{pmatrix}alpha^{-7} +alpha^{4}x+ alpha^{-1}x^2+ alpha^{6}x^3+ alpha^{-1}x^4+alpha^{5}x^5 +alpha^{7}x^6+ alpha^{-3}x^7 \ x^6end{pmatrix} \ [6pt] &=begin{pmatrix}alpha^{7}+alpha^{-3}x&1\ 1&0end{pmatrix} begin{pmatrix}x^6\ alpha^{-7} +alpha^{4}x +alpha^{-1}x^2 +alpha^{6}x^3 +alpha^{-1}x^4 +alpha^{5}x^5 +2alpha^{7}x^6 +2alpha^{-3}x^7end{pmatrix} \ [6pt] &=begin{pmatrix}alpha^{7}+alpha^{-3}x&1\ 1&0end{pmatrix} begin{pmatrix}alpha^4+alpha^{-5}x&1\ 1&0end{pmatrix} times &qquad times begin{pmatrix} alpha^{-7}+alpha^{4}x+alpha^{-1}x^2+alpha^{6}x^3+alpha^{-1}x^4+alpha^{5}x^5\ alpha^{-3} +(alpha^{-7}+alpha^{3})x+(alpha^{3}+alpha^{-1})x^2+(alpha^{-5}+alpha^{-6})x^3+(alpha^3+alpha^{1})x^4+ 2alpha^{-6}x^5+ 2x^6end{pmatrix} \ [6pt] &=begin{pmatrix}(1+alpha^{-4})+(alpha^{1}+alpha^{2})x+alpha^{7}x^2&alpha^{7}+alpha^{-3}x \ alpha^4+alpha^{-5}x&1end{pmatrix} begin{pmatrix} alpha^{-7} +alpha^{4}x +alpha^{-1}x^2+ alpha^{6}x^3+alpha^{-1}x^4+alpha^{5}x^5\ alpha^{-3}+alpha^{-2}x+alpha^{0}x^2+ alpha^{-2}x^3+alpha^{-6}x^4end{pmatrix} \ [6pt] &=begin{pmatrix}alpha^{-3}+alpha^{5}x+alpha^{7}x^2&alpha^{7}+alpha^{-3}x \ alpha^4+alpha^{-5}x&1end{pmatrix} begin{pmatrix}alpha^{-5}+alpha^{-4}x&1\ 1&0 end{pmatrix} times &qquad times begin{pmatrix} alpha^{-3}+alpha^{-2}x+alpha^{0}x^2+ alpha^{-2}x^3+alpha^{-6}x^4\ (alpha^{7}+alpha^{-7})+ (2alpha^{-7}+alpha^{4})x+ (alpha^{-5}+alpha^{-6}+alpha^{-1})x^2+ (alpha^{-7}+alpha^{-4}+alpha^{6})x^3+ (alpha^{4}+alpha^{-6}+alpha^{-1})x^4+ 2alpha^{5}x^5end{pmatrix} \ [6pt] &=begin{pmatrix} alpha^{7}x+alpha^{5}x^2+alpha^{3}x^3&alpha^{-3}+alpha^{5}x+alpha^{7}x^2\ alpha^{3}+alpha^{-5}x+alpha^{6}x^2&alpha^4+alpha^{-5}xend{pmatrix} begin{pmatrix} alpha^{-3}+alpha^{-2}x+alpha^{0}x^2+ alpha^{-2}x^3+alpha^{-6}x^4\ alpha^{-4}+alpha^{4}x+alpha^{2}x^2+ alpha^{-5}x^3end{pmatrix}. end{align}](/upload/en/images/math/9/8/b/98bc35296a2d1ad38cfdd11ef2a1322c.png)
We have reached polynomial of degree at most 3, and as

we get

Therefore,

Let  Don’t worry that
Don’t worry that  Find by brute force a root of The roots are
Find by brute force a root of The roots are  and
and  (after finding for example
(after finding for example  we can divide by corresponding monom
we can divide by corresponding monom  and the root of resulting monom could be found easily).
and the root of resulting monom could be found easily).
Let


Let us look for error values using formula

where are roots of 
 We get
We get

Fact, that  should not be surprising.
should not be surprising.
Corrected code is therefore [ 1 0 1 1 0 0 1 0 1 0 0].
Decoding with unreadable characters with a small number of errors
Let us show the algorithm behaviour for the case with small number of errors. Let the received word is [ 1 0 ? 1 1 ? 0 0 0 1 0 1 0 0 ].
Again, replace the unreadable characters by zeros while creating the polynom reflecting their positions Compute the syndromes  and
and  Create syndrome polynomial
Create syndrome polynomial


Let us run the extended Euclidean algorithm:

We have reached polynomial of degree at most 3, and as

we get

Therefore,

Let  Don’t worry that The root of is
Don’t worry that The root of is 
Let


Let us look for error values using formula  where are roots of polynomial
where are roots of polynomial  We get
We get

The fact that  should not be surprising.
should not be surprising.
Corrected code is therefore [ 1 0 1 1 0 0 0 1 0 1 0 0].