
Cryptographic hash function
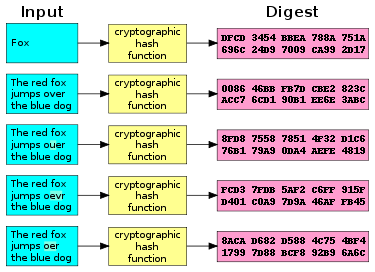
Cryptographic hash function is a special class of hash function that has certain properties which make it suitable for use in cryptography. It is a mathematical algorithm that maps data of arbitrary size to a bit string of a fixed size (a hash) and is designed to be a one-way function, that is, a function which is infeasible to invert.
In practice, collision resistance is insufficient for many practical uses.
In addition to collision resistance, it should be impossible for an adversary to find two messages with substantially similar digests; or to infer any useful information about the data, given only its digest. In particular, should behave as much as possible like a random function (often called a random oracle in proofs of security) while still being deterministic and efficiently computable. This rules out functions like the SWIFFT function, which can be rigorously proven to be collision resistant assuming that certain problems on ideal lattices are computationally difficult, but as a linear function, does not satisfy these additional properties.
Checksum algorithms, such as CRC32 and other cyclic redundancy checks, are designed to meet much weaker requirements, and are generally unsuitable as cryptographic hash functions. For example, a CRC was used for message integrity in the Wired Equivalent Privacy (WEP) encryption standard, but an attack was readily discovered which exploited the linearity of the checksum.
Contents
Hash Function Review
An illustration of the potential use of a cryptographic hash is as follows: Alice poses a tough math problem to Bob and claims she has solved it. Bob would like to try it himself, but would yet like to be sure that Alice is not bluffing. Therefore, Alice writes down her solution, computes its hash and tells Bob the hash value (whilst keeping the solution secret). Then, when Bob comes up with the solution himself a few days later, Alice can prove that she had the solution earlier by revealing it and having Bob hash it and check that it matches the hash value given to him before. (This is an example of a simple commitment scheme; in actual practice, Alice and Bob will often be computer programs, and the secret would be something less easily spoofed than a claimed puzzle solution).
Degree of difficulty
In cryptographic practice, “difficult” generally means “almost certainly beyond the reach of any adversary who must be prevented from breaking the system for as long as the security of the system is deemed important”. The meaning of the term is therefore somewhat dependent on the application, since the effort that a malicious agent may put into the task is usually proportional to his expected gain. However, since the needed effort usually grows very quickly with the digest length, even a thousand-fold advantage in processing power can be neutralized by adding a few dozen bits to the latter.
For messages selected from a limited set of messages, for example passwords or other short messages, it can be feasible to invert a hash by trying all possible messages in the set. Because cryptographic hash functions are typically designed to be computed quickly, special key derivation functions that require greater computing resources have been developed that make such brute force attacks more difficult.
In some theoretical analyses “difficult” has a specific mathematical meaning, such as “not solvable in asymptotic polynomial time”. Such interpretations of difficulty are important in the study of provably secure cryptographic hash functions but do not usually have a strong connection to practical security. For example, an exponential time algorithm can sometimes still be fast enough to make a feasible attack. Conversely, a polynomial time algorithm (e.g., one that requires n20 steps for n-digit keys) may be too slow for any practical use.
Applications
Verifying the integrity of files or messages
An important application of secure hashes is verification of message integrity. Determining whether any changes have been made to a message (or a file), for example, can be accomplished by comparing message digests calculated before, and after, transmission (or any other event).
For this reason, most digital signature algorithms only confirm the authenticity of a hashed digest of the message to be “signed”. Verifying the authenticity of a hashed digest of the message is considered proof that the message itself is authentic.
MD5, SHA-1, or SHA-2 hashes are sometimes posted along with files on websites or forums to allow verification of integrity. This practice establishes a chain of trust so long as the hashes are posted on a site authenticated by HTTPS.
Password verification
A related application is password verification (first invented by Roger Needham). Storing all user passwords as cleartext can result in a massive security breach if the password file is compromised. One way to reduce this danger is to only store the hash digest of each password. To authenticate a user, the password presented by the user is hashed and compared with the stored hash. (Note that this approach prevents the original passwords from being retrieved if forgotten or lost, and they have to be replaced with new ones.) The password is often concatenated with a random, non-secret salt value before the hash function is applied. The salt is stored with the password hash. Because users will typically have different salts, it is not feasible to store tables of precomputed hash values for common passwords when salt is employed. On the other hand, standard cryptographic hash functions are designed to be computed quickly, and, as a result, it is possible to try guessed passwords at high rates. Common graphics processing units can try billions of possible passwords each second. Key stretching functions, such as PBKDF2, bcrypt or scrypt, typically use repeated invocations of a cryptographic hash to increase the time, and in some cases computer memory, required to perform brute force attacks on stored password digests.
In 2013 a Password Hashing Competition was announced to choose a new, standard algorithm for password hashing. The winner, selected in July 2015, was a new key stretching algorithm, Argon2. In June 2017, NIST issued a new revision of their digital authentication guidelines, NIST SP 800-63B-3, stating: “Verifiers SHALL store memorized secrets [i.e. passwords] in a form that is resistant to offline attacks. Memorized secrets SHALL be salted and hashed using a suitable one-way key derivation function.”
Proof-of-work
A proof-of-work system (or protocol, or function) is an economic measure to deter denial-of-service (DDoS) attacks and other service abuses such as spam on a network by requiring some work from the service requester, usually meaning processing time by a computer. A key feature of these schemes is their asymmetry: the work must be moderately hard (but feasible) on the requester side but easy to check for the service provider. One popular system – used in Bitcoin mining and Hashcash – uses partial hash inversions to prove that work was done, to unlock a mining reward in Bitcoin and as a good-will token to send an e-mail in Hashcash. The sender is required to find a message whose hash value begins with a number of zero bits. The average work that sender needs to perform in order to find a valid message is exponential in the number of zero bits required in the hash value, while the recipient can verify the validity of the message by executing a single hash function. For instance, in Hashcash, a sender is asked to generate a header whose 160 bit SHA-1 hash value has the first 20 bits as zeros. The sender will on average have to try 219 times to find a valid header.
File or data identifier
A message digest can also serve as a means of reliably identifying a file; several source code management systems, including Git, Mercurial and Monotone, use the sha1sum of various types of content (file content, directory trees, ancestry information, etc.) to uniquely identify them. Hashes are used to identify files on peer-to-peer filesharing networks. For example, in an ed2k link, an MD4-variant hash is combined with the file size, providing sufficient information for locating file sources, downloading the file and verifying its contents. Magnet links are another example. Such file hashes are often the top hash of a hash list or a hash tree which allows for additional benefits.
One of the main applications of a hash function is to allow the fast look-up of a data in a hash table. Being hash functions of a particular kind, cryptographic hash functions lend themselves well to this application too.
However, compared with standard hash functions, cryptographic hash functions tend to be much more expensive computationally. For this reason, they tend to be used in contexts where it is necessary for users to protect themselves against the possibility of forgery (the creation of data with the same digest as the expected data) by potentially malicious participants.
Pseudorandom generation and key derivation
Hash functions can also be used in the generation of pseudorandom bits, or to derive new keys or passwords from a single secure key or password.
Hash functions based on block ciphers
There are several methods to use a block cipher to build a cryptographic hash function, specifically a one-way compression function.
The methods resemble the block cipher modes of operation usually used for encryption. Many well-known hash functions, including MD4, MD5, SHA-1 and SHA-2 are built from block-cipher-like components designed for the purpose, with feedback to ensure that the resulting function is not invertible. SHA-3 finalists included functions with block-cipher-like components (e.g., Skein, BLAKE) though the function finally selected, Keccak, was built on a cryptographic sponge instead.
A standard block cipher such as Advanced Encryption Standard (AES can be used in place of these custom block ciphers; that might be useful when an embedded system needs to implement both encryption and hashing with minimal code size or hardware area. However, that approach can have costs in efficiency and security. The ciphers in hash functions are built for hashing: they use large keys and blocks, can efficiently change keys every block, and have been designed and vetted for resistance to related-key attacks. General-purpose ciphers tend to have different design goals. In particular, AES has key and block sizes that make it nontrivial to use to generate long hash values; AES encryption becomes less efficient when the key changes each block; and related-key attacks make it potentially less secure for use in a hash function than for encryption.
Hash function design
Merkle–Damgård construction
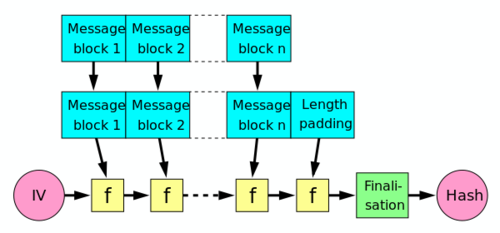
A hash function must be able to process an arbitrary-length message into a fixed-length output. This can be achieved by breaking the input up into a series of equal-sized blocks, and operating on them in sequence using a one-way compression function. The compression function can either be specially designed for hashing or be built from a block cipher. A hash function built with the Merkle–Damgård construction is as resistant to collisions as is its compression function; any collision for the full hash function can be traced back to a collision in the compression function.
The last block processed should also be unambiguously length padded; this is crucial to the security of this construction. This construction is called the Merkle–Damgård construction. Most common classical hash functions, including SHA-1 and MD5, take this form.
Wide pipe vs narrow pipe
A straightforward application of the Merkle–Damgård construction, where the size of hash output is equal to the internal state size (between each compression step), results in a narrow-pipe hash design. This design causes many inherent flaws, including length-extension, multicollisions, long message attacks, generate-and-paste attacks, and also cannot be parallelized. As a result, modern hash functions are built on wide-pipe constructions that have a larger internal state size — which range from tweaks of the Merkle–Damgård construction None of the entrants in the NIST hash function competition use a classical Merkle–Damgård construction.
Meanwhile, truncating the output of a longer hash, such as used in SHA-512/256, also defeats many of these attacks.
Use in building other cryptographic primitives
Hash functions can be used to build other cryptographic primitives. For these other primitives to be cryptographically secure, care must be taken to build them correctly.
Message authentication codes (MACs) (also called keyed hash functions) are often built from hash functions. HMAC is such a MAC.
Just as block ciphers can be used to build hash functions, hash functions can be used to build block ciphers. Luby-Rackoff constructions using hash functions can be provably secure if the underlying hash function is secure. Also, many hash functions (including SHA-1 and SHA-2) are built by using a special-purpose block cipher in a Davies–Meyer or other construction. That cipher can also be used in a conventional mode of operation, without the same security guarantees. See SHACAL, BEAR and LION.
Pseudorandom number generators (PRNGs) can be built using hash functions. This is done by combining a (secret) random seed with a counter and hashing it.
Some hash functions, such as , Keccak, and RadioGatún output an arbitrarily long stream and can be used as a stream cipher, and stream ciphers can also be built from fixed-length digest hash functions. Often this is done by first building a cryptographically secure pseudorandom number generator and then using its stream of random bytes as keystream. SEAL is a stream cipher that uses SHA-1 to generate internal tables, which are then used in a keystream generator more or less unrelated to the hash algorithm. SEAL is not guaranteed to be as strong (or weak) as SHA-1. Similarly, the key expansion of the HC-128 and HC-256 stream ciphers makes heavy use of the SHA-256 hash function.
Concatenation
Concatenating outputs from multiple hash functions provides collision resistance as good as the strongest of the algorithms included in the concatenated result. For example, older versions of Transport Layer Security (TLS) and Secure Sockets Layer (SSL) use concatenated MD5 and SHA-1 sums. This ensures that a method to find collisions in one of the hash functions does not defeat data protected by both hash functions.
For Merkle–Damgård construction hash functions, the concatenated function is as collision-resistant as its strongest component, but not more collision-resistant. Antoine Joux observed that 2-collisions lead to n-collisions: if it is feasible for an attacker to find two messages with the same MD5 hash, the attacker can find as many messages as the attacker desires with identical MD5 hashes with no greater difficulty. Among the n messages with the same MD5 hash, there is likely to be a collision in SHA-1. The additional work needed to find the SHA-1 collision (beyond the exponential birthday search) requires only polynomial time.
Cryptographic hash algorithms
There is a long list of cryptographic hash functions, although many have been found to be vulnerable and should not be used. Even if a hash function has never been broken, a successful attack against a weakened variant may undermine the experts’ confidence and lead to its abandonment. For instance, in August 2004 weaknesses were found in several then-popular hash functions, including SHA-0, RIPEMD, and MD5. These weaknesses called into question the security of stronger algorithms derived from the weak hash functions—in particular, SHA-1 (a strengthened version of SHA-0), RIPEMD-128, and RIPEMD-160 (both strengthened versions of RIPEMD). Neither SHA-0 nor RIPEMD are widely used since they were replaced by their strengthened versions.
As of 2009, the two most commonly used cryptographic hash functions were MD5 and SHA-1. However, a successful attack on MD5 broke Transport Layer Security in 2008.
The United States National Security Agency (NSA) developed SHA-0 and SHA-1.
On 12 August 2004, Joux, Carribault, Lemuet, and Jalby announced a collision for the full SHA-0 algorithm. Joux et al. accomplished this using a generalization of the Chabaud and Joux attack. They found that the collision had complexity 251 and took about 80,000 CPU hours on a supercomputer with 256 Itanium 2 processors—equivalent to 13 days of full-time use of the supercomputer.
In February 2005, an attack on SHA-1 was reported that would find collision in about 269 hashing operations, rather than the 280 expected for a 160-bit hash function. In August 2005, another attack on SHA-1 was reported that would find collisions in 263 operations. Theoretical weaknesses of SHA-1 exist, and in February 2017 Google announced a collision in SHA-1. Security researchers recommend that new applications can avoid these problems by using later members of the SHA family, such as SHA-2, or using techniques such as randomized hashing that do not require collision resistance.
However, to ensure the long-term robustness of applications that use hash functions, there was a competition to design a replacement for SHA-2. On October 2, 2012, Keccak was selected as the winner of the National Institute of Standards and Technology (NIST) hash function competition. A version of this algorithm became a Federal Information Processing Standards (FIPS) standard on August 5, 2015 under the name SHA-3.
Another finalist from the NIST hash function competition, BLAKE, was optimized to produce BLAKE2 which is notable for being faster than SHA-3, SHA-2, SHA-1, or MD5, and is used in numerous applications and libraries.
See Also on BitcoinWiki
- Comparison of cryptographic hash functions
- Hash chain
- Random oracle
- Message authentication code
- Security of cryptographic hash functions
- SHA-3
- Universal one-way hash function